使用支持向量回归(SVR)进行机器学习
在这篇博客中,我们将探讨如何使用支持向量回归(SVR)算法进行机器学习,以及如何在实际数据集上应用此算法。我们将使用 Python 编程语言和 scikit-learn 库,这是一个流行且功能强大的机器学习库。
1. 什么是支持向量回归(SVR)?
支持向量回归是一种用于回归问题的机器学习方法,它使用支持向量机(SVM)的原理。与分类问题的 SVM 不同,SVR 预测的是一个连续的数值而非离散的类别。SVR 试图找到一个函数,这个函数在整个数据集上有最小的偏差。
2. 数据集和准备
我们将使用 scikit-learn 提供的波士顿房价数据集。这是一个关于房价的数据集,包含房屋以及它们的各种属性。
1
2
3
| from sklearn.datasets import fetch_california_housing
data = load_boston()
X, y = data.data, data.target
|
3. 数据预处理
在开始建模之前,我们需要对数据进行分割和标准化处理:
1
2
3
4
5
6
7
8
9
10
11
12
| from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
scaler_X = StandardScaler()
X_train = scaler_X.fit_transform(X_train)
X_test = scaler_X.transform(X_test)
scaler_y = StandardScaler()
y_train = scaler_y.fit_transform(y_train.reshape(-1, 1)).flatten()
y_test = scaler_y.transform(y_test.reshape(-1, 1)).flatten()
|
4. 构建和训练 SVR 模型
现在我们可以创建 SVR 模型,并用训练数据来训练它:
1
2
3
4
| from sklearn.svm import SVR
svr = SVR(kernel='rbf')
svr.fit(X_train, y_train)
|
5. 模型评估
使用测试集评估模型的性能:
1
2
3
4
5
6
7
| from sklearn.metrics import mean_squared_error, r2_score
y_pred = svr.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"均方误差(MSE): {mse}")
print(f"R^2 分数: {r2}")
|
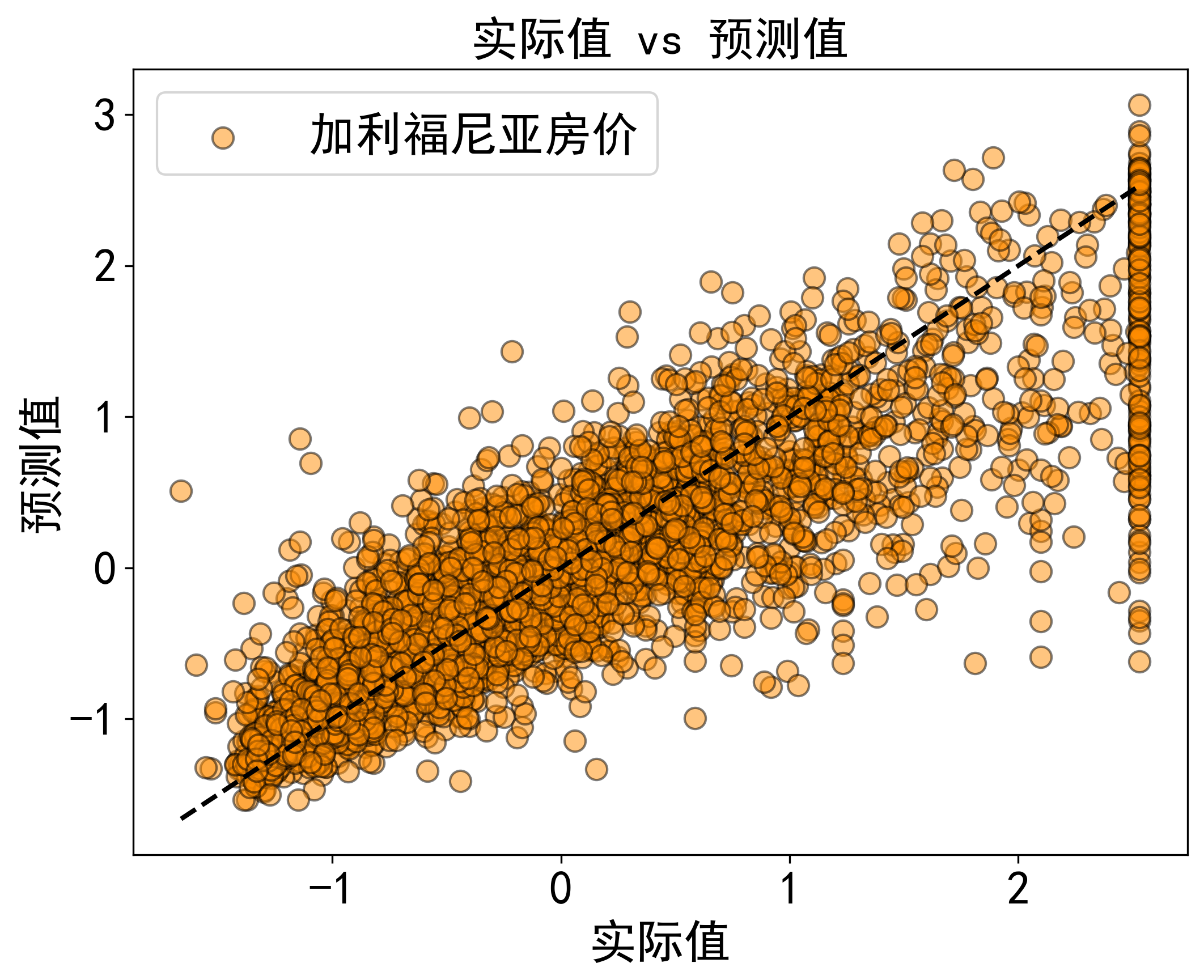
6. 结果可视化
我们可以通过绘制实际值和预测值的对比图来可视化模型性能:
1
2
3
4
5
6
7
8
| import matplotlib.pyplot as plt
plt.scatter(y_test, y_pred)
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'k--', lw=2)
plt.xlabel('实际值')
plt.ylabel('预测值')
plt.title('实际值 vs 预测值')
plt.show()
|
7. 总结
在这篇博客中,我们学习了如何使用支持向量回归(SVR)来处理回归问题,并在波士顿房价数据集上实践了这一方法。SVR 提供了一种有效的方式来预测连续数据,并在许多实际应用中表现出色。
脚本下载SVR_California_Housing.py
脚本下载SVR_California_Housing.ipynb